Introduction
For an existing project, my coauthors and I use a number of statistical tools in conjunction with a structural model in order to recover preference parameters from experimental data. As described in extensive detail in the draft, we have designed a two-stage experiment in the classic endowment effect framework in an attempt to test the comparative statics of the KR model; our primary contribution is a theoretical and empirical demonstration that accounting for heterogeneity in individual gain-loss attitudes is crucial for generating/recovering predictions in this paradigm. In order to convincingly demonstrate this, we use our first stage experimental data to estimate gain-loss attitudes, from which we generate sharp, testable predictions that form our second stage hypothesis.
As the measurement of gain-loss attitudes is fundamental to our hypothesis, we experiment with a number of methods. Originally, we opted for a standard MLE procedure relying on random utility methods and our structural model. However, these estimates did not directly allow us to speak about the core heterogeneity in which we were interested. Because of this, we adapted our estimation procedure to a similar methodology more suited to measuring distributions: mixed logit. The key difference in this framework is that we assume our central parameter is normally distributed, with unobservable, individual-level noise. This problem has no analytical solution, so we adopt Monte Carlo simulation methods — sampling from our assumed noise distribution to generate a Maximum Simulated Likelihood function which we ultimately maximize.
Once we have estimated the distribution of gain-loss attitudes, we assign individual level parameters by computed the expected value of gain-loss attitude that would lead to the observed decision (given the choice context). With this in hand, we can run our regression of interest relying on the estimated value of gain-loss attitude rather than a coarser classification as in the paper.
Code
The following code implements the MSL estimation procedure, as well as the individual parameter assignment and interaction regression of interest. The code is implemented in R, although our most recent effort in this direction has a slightly different flavor and is implemented in Stata.
library(foreign)
library("haven")
library(dplyr)
#gather the data from the wd, currently formatted as a dta from Stata.
orig_data <- read_dta("original_dataset.dta")
#set the number of random draws
num_draws=1000
#Define the Random Parameter Mixed Simulated Likelihood Function.
mslf <- function(param){
#Set up the major variables that will be used to created a likelihood
choice<-Data$preference_liking
endowment<-Data$InitialGood_Stage1
#set of parameters we are hoping to find the MSL estimates of.
lambda_m<-param[1]
u1<-param[2]
u2<-param[3]
u3<-param[4]
u4<-param[5]
delt<-param[6]
sd<-exp(param[7])
sim_avg_f=0
set.seed(10101)
#create the for loop over which we generate the simulated likelihood function
for(i in 1:num_draws){
#first, generate a set of random normal variables for each individual
#This will represent the underlying (unobserved) heterogeneity in our random parameter model.
unobserved_noise<-rnorm(nrow(Data), 0, 1)
#Draw lambda value for an individual, sampling from the mean value (lambda_temp) with noise e*sd.
lambda<-lambda_m+unobserved_noise*sd
#Given individual context, generate the KR structural utilities.
#Good a represents the endowment, so we compute U(a|a).
kr_utils_good_a=u1*(endowment==1)+u2*(endowment==2)+u3*(endowment==3)+u4*(endowment==4)
#Good b represents the alternative good, so we compute U(b|a)
kr_utils_good_b=(2*u2-lambda*u1)*(endowment==1)+(2*u1-lambda*u2)*(endowment==2)+
(2*u4-lambda*u3)*(endowment==3)+(2*u3-lambda*u4)*(endowment==4)
#Construct the likelihood at the given draw
sim_f=(exp(kr_utils_good_a)/(exp(kr_utils_good_a)+exp(kr_utils_good_b+delt)))*(choice==1)+
(exp(kr_utils_good_b)/(exp(kr_utils_good_b)+exp(kr_utils_good_a+delt)))*(choice==-1)+
(1- (exp(kr_utils_good_b)/(exp(kr_utils_good_b)+exp(kr_utils_good_a+delt)))-
(exp(kr_utils_good_a)/(exp(kr_utils_good_a)+exp(kr_utils_good_b+delt))) )*(choice==0)
sim_avg_f = sim_avg_f + sim_f/num_draws
}
log(sim_avg_f)
}
#Select the relevant attributes to feed into the MSL function.
Data<-select(orig_data, c(InitialGood_Stage1, Treatment, preference_liking))
#MSL of Lambda for "Prefer Endowment"
msl_results <- maxBFGSR(mslf, start=c(1.5,1, 1, 1, 1, 0.75, 0.75), print.level=2, activePar=c(T,F,T,T, F, T,T), tol=1e-5)
summary(msl_results)
#Present the MSL coefficient estimates and their associated Standard Errors
coeffs <- msl_results$estimate
covmat<-solve(-(hessian(msl_results)[activePar(msl_results), activePar(msl_results)]))
stderr <- sqrt(diag(covmat))
for(i in 1:length(which(activePar(msl_results)==FALSE))){
stderr<- append(stderr, NA, after=((which(activePar(msl_results)==FALSE)[i])-1))
}
zscore <- coeffs/stderr
pvalue <- 2*(1 - pnorm(abs(zscore)))
results_bundle1_ind <- cbind(coeffs,stderr,zscore,pvalue)
colnames(results_bundle1_ind) <- c("Coeff.", "Std. Err.", "z", "p value")
print(results_bundle1_ind)
#With the MSL estimates in hand, we can run the second stage regressions of interest.
#In particular, we have estimates of the distribution of lambda, as well as the relative
#utilities and indifference thresholds. From here, we can relate the pattern of choices made
#to an expected value of lambda for that particular choice. For instance, someone endowed good
#1 and stating a preference for good 1 would have specifc expected lambda related to the
#utility of good 1 vs good 2, which we compute in this section.
#These variables represent our estimated quantities
l_est <- coeffs[[1]]
u1 <- coeffs[[2]]
u2 <- coeffs[[3]]
u3 <- coeffs[[4]]
u4 <- coeffs[[5]]
d <- coeffs[[6]]
sd_est <- exp(coeffs[[7]])
#we draw a large number of lambdas from the distribution we estimated with the MSL.
lambdas <- rnorm(num_draws, mean = l_est, sd= sd_est)
######################################
#Endowed 1: Expected Lambda Given Choice
######################################
#First, compute the logit probability of Preferring 1,2 or indifference from our lambda distribution.
# Probability of Preferring 1 given Endowed 1
p_11 <- exp(u1)/(exp(u1) + exp(2*u2 - lambdas*u1 + d))
##Probability of Preferring 2 given Endowed 1
p_21 <- exp(2*u2 - lambdas*u1)/(exp(u1+d) + exp(2*u2 - lambdas*u1) )
##Probability of Preferring Neither
p_no1 <- 1 -p_11 - p_21
# Following Train (2002) (Discrete Choice Models with Simulation, Chapter 6), we compute the
#expected value by integrating over the mixed logit probabilities (p_11, etc) for each lambda,
#weighted by the distribution estimated.
# Expected Lambda for Prefer 1 given Endowed 1
l_11 <- sum((p_11/sum(p_11))*lambdas)
# Expected Lambda for Preferring 2 given Endowed 1
l_21 <- sum((p_21/sum(p_21))*lambdas)
# Expected Lambda for Preferring Neither given Endowed 1
l_no1 <- sum((p_no1/sum(p_no1))*lambdas) #Although not used for the analysis, our distributional estimates allow us to quantify #the likelihood Probability that an individual is loss averse (lambda>1) given their options.
#Probability Loss Averse for Preferring 1 given Endowed 1
pla_11 <- sum((p_11/sum(p_11))*ifelse(lambdas>1,1,0))
#Probability Loss Aversefor Preferring 2 given Endowed 1
pla_21 <- sum((p_21/sum(p_21))*ifelse(lambdas>1,1,0))
#Probability Loss Averse for Preferring Neither given Endowed 1
pla_no1 <- sum((p_no1/sum(p_no1))*ifelse(lambdas>1,1,0))
#We now repeat these computations for each of the endowments
######################################
#Endowed 2: Expected Lambda Given Choice
######################################
##Probability of Preferring 2 given Endowed 2
p_22 <- exp(u2)/(exp(u2) + exp(2*u1 - lambdas*u2 + d))
##Probability of Preferring 1 given Endowed 2
p_12 <- exp(2*u1 - lambdas*u2)/(exp(u2+d) + exp(2*u1 - lambdas*u2) )
##Probability of Preferring Neither
p_no2 <- 1 -p_22 - p_12
#Expected Lambda for Preferring 2 given Endowed 2
l_22 <- sum((p_22/sum(p_22))*lambdas)
#Expected Lambda for Preferring 1 given Endowed 2
l_12 <- sum((p_12/sum(p_12))*lambdas)
#Expected Lambda for Preferring Neither given Endowed 2
l_no2 <- sum((p_no2/sum(p_no2))*lambdas)
#Probability Loss Averse for Preferring 2 given Endowed 2
pla_22 <- sum((p_22/sum(p_22))*ifelse(lambdas>1,1,0))
#Probability Loss Aversefor Preferring 1 given Endowed 2
pla_12 <- sum((p_12/sum(p_12))*ifelse(lambdas>1,1,0))
#Probability Loss Averse for Preferring Neither given Endowed 2
pla_no2 <- sum((p_no2/sum(p_no2))*ifelse(lambdas>1,1,0))
######################################
#Endowed 3: Expected Lambda Given Choice
######################################
##Probability of Preferring 3 given Endowed 3
p_33 <- exp(u3)/(exp(u3) + exp(2*u4 - lambdas*u3 + d))
##Probability of Preferring 4 given Endowed 3
p_43 <- exp(2*u4 - lambdas*u3)/(exp(u3+d) + exp(2*u4 - lambdas*u3) )
##Probability of Preferring Neither
p_no3 <- 1 -p_33 - p_43
#Expected Lambda for Preferring 3 given Endowed 3
l_33 <- sum((p_33/sum(p_33))*lambdas)
#Expected Lambda for Preferring 4 given Endowed 3
l_43 <- sum((p_43/sum(p_43))*lambdas)
#Expected Lambda for Preferring Neither given Endowed 3
l_no3 <- sum((p_no3/sum(p_no3))*lambdas)
#Probability Loss Averse for Preferring 3 given Endowed 3
pla_33 <- sum((p_33/sum(p_33))*ifelse(lambdas>1,1,0))
#Probability Loss Aversefor Preferring 4 given Endowed 3
pla_43 <- sum((p_43/sum(p_43))*ifelse(lambdas>1,1,0))
#Probability Loss Averse for Preferring Neither given Endowed 3
pla_no3<-sum((p_no3/sum(p_no3))*ifelse(lambdas>1,1,0))
######################################
#Endowed 4
######################################
##Probability of Preferring 4 given Endowed 4
p_44 <- exp(u4)/(exp(u4) + exp(2*u3 - lambdas*u4 + d))
##Probability of Preferring 3 given Endowed 4
p_34 <- exp(2*u3 - lambdas*u4)/(exp(u4+d) + exp(2*u3 - lambdas*u4) )
##Probability of Preferring Neither
p_no4 <- 1 -p_44 - p_34
#Expected Lambda for Preferring 4 given Endowed 4
l_44 <- sum((p_44/sum(p_44))*lambdas)
#Expected Lambda for Preferring 3 given Endowed 4
l_34 <- sum((p_34/sum(p_34))*lambdas)
#Expected Lambda for Preferring Neither given Endowed 4
l_no4 <- sum((p_no4/sum(p_no4))*lambdas)
#Probability Loss Averse for Preferring 4 given Endowed 4
pla_44 <- sum((p_44/sum(p_44))*ifelse(lambdas>1,1,0))
#Probability Loss Aversefor Preferring 3 given Endowed 4
pla_34 <- sum((p_34/sum(p_34))*ifelse(lambdas>1,1,0))
#Probability Loss Averse for Preferring Neither given Endowed 4
pla_no4<-sum((p_no4/sum(p_no4))*ifelse(lambdas>1,1,0))
#Having computed the expected lambda given the possible combination of rating preference
#and endowment, we can now assign these values to the individuals in the lab, who actually
#made these preference statements. This will yield 12 values of lambda in the data set.
#With these lambdas assigned, as well as the treatment indicator, we can analyze the second
#stage behavior using the interaction specification of interest. Specifically, we regress
#Voluntary_Exchange on the estimated lambda, treatment, and the interaction of the two.
orig_data<-orig_data %>% mutate(Measured_Lambda=case_when(
(InitialGood_Stage1==1 & preference_liking==1) ~ l_11,
(InitialGood_Stage1==1 & preference_liking==-1) ~ l_21,
(InitialGood_Stage1==1 & preference_liking==0) ~ l_no1,
(InitialGood_Stage1==2 & preference_liking==1) ~ l_22,
(InitialGood_Stage1==2 & preference_liking==-1) ~ l_12,
(InitialGood_Stage1==2 & preference_liking==0) ~ l_no2,
(InitialGood_Stage1==3 & preference_liking==1) ~ l_33,
(InitialGood_Stage1==3 & preference_liking==-1) ~ l_43,
(InitialGood_Stage1==3 & preference_liking==0) ~ l_no3,
(InitialGood_Stage1==4 & preference_liking==1) ~ l_44,
(InitialGood_Stage1==4 & preference_liking==-1) ~ l_34,
(InitialGood_Stage1==4 & preference_liking==0) ~ l_no4,
))
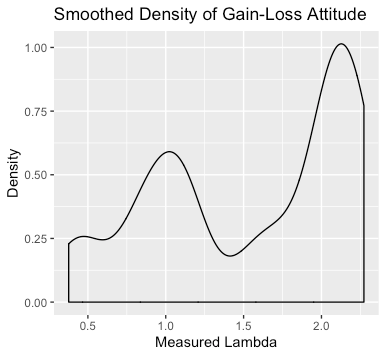
#First, plot a kernel smoothed density of the Lambda.
library(ggplot2)
density_plot<-ggplot(orig_data, aes(Measured_Lambda)) + geom_density()+
labs(x="Measured Lambda", y="Density", title = "Smoothed Density of Gain-Loss Attitude")
#Finally, run the regression of interest.
interaction_reg=lm(VoluntaryExchange~Treatment+Measured_Lambda+(Treatment*Measured_Lambda), data = orig_data)
summary(interaction_reg)
library("stargazer")
stargazer(interaction_reg, title="MSL Interaction Regression",
align=TRUE, dep.var.labels=c("Exchange (=1)"),
covariate.labels=c("Treatment","$\\hat{\\lambda}_i$",
"$\\hat{\\lambda}_i \\times$ Treatment"),
omit.stat=c("LL","ser", "aic", "bic"), no.space=TRUE)

Sources:
Goette, Lorenz, Thomas Graeber, Alexandre Kellogg, and Charles Sprenger (2018). “Heterogeneity of Gain-Loss Attitudes and Expectations-Based Reference Points”.
Kőszegi, Botond and Matthew Rabin (2006). “A model of reference-dependent preferences”. In: The Quarterly Journal of Economics, pp. 1133–1165.
Kőszegi, Botond and Matthew Rabin (2007). “Reference-Dependent Risk Attitudes.” In: American Economic Review (4): 1047–73.